Tutorials
Tools for Capture the Flag Events (and beyond)
Introduction
CTF stands for "Capture the Flag," and digital/server based CTF competitions have been a thing for awhile. These competitions usually require the use of computer-based tools to help solve puzzles.
The Polytechnic School Capture-the-Flag
The challenges in this particular CTF vary widely in difficulty. Some problems are simple logic or encoding puzzles, others may require some research on the Internet or searching for information online, some may require using a text editor to interact with information, and some may require reading or writing code to help you solve the puzzle.
This tutorial emphasizes using the Linux/Unix (OS X) command line with shell-based tools to perform certain types of digital analysis. Other custom tools and applications will occasionally be mentioned as well, but the focus will be on using the shell, available in Linux and OS X operating system. To perform these analyses on a Windows-based machine, use Ubuntu Bash for Windows 10 (which has most of these tools available), or consider installing a virtual machine/Linux set-up that will allow you to use a native terminal.
ASCII, Decimal, Binary, Octal, Hexadecimal Values
Here. I made a table for you: ascii_table.txt
Text Editing
You will need to be able to open up, read, search, and edit text-based documents. The ultimate tool for text editing, at least in a Terminal window, is going to be either vim or emacs, which you can launch from the command line by entering the name of either editor at the command line.
Both of these programs have a steep-learning curve that ultimately rewards your efforts, but they're a bit much for us to hassle with right now. Instead, use one of the free text editors available for your system:
- Cross platform - Visual Studio Code, Sublime
These are text-editor applications that are powerful and offer some nice themes, support for syntax-highlighitng, etc. They may choke on especially large files... - macOS, OS X - BBEdit
Awesome text-editing apps for your Apple machine. - Linux - gedit
At the command line, run sudo apt-get install gedit - Windows - Notepad++
Classic Windows utility.
All of these programs support the use of a mouse, and will allow you to work on text files with a power and speed that is almost as good as vim or emacs.
Looking at Source Code
With a text editor you can:
- Look at the text-based documents
- Use massively powerful search, find, and find-replace options
- Examine program code
- Look at HTML code for webpages
Webpage source code
Firefox, Chrome, and Safari browsers all give you the ability to look at the source code of webpages, typically using a "Developer Tool" option tucked away in one of the menus.
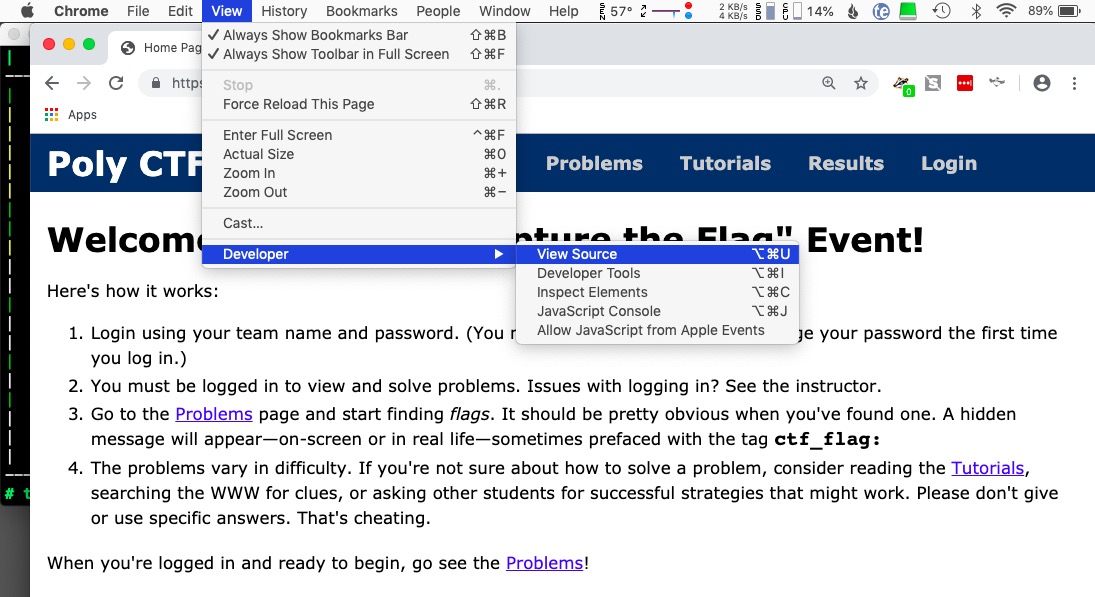
If you feel a webpage is doing something sneaky—redirecting you to a different page, for example—you can turn off JavaScript execution, disable cookies, etc.
Another way that you can access a page without actually opening it in your browser is by using something like the curl command in the Terminal:
$ curl -O https://www.crashwhite.com/ctf/index.php
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 3931 100 3931 0 0 1017 0 0:00:03 0:00:03 --:--:-- 1017
$
(This downloads the given page to the current directory where you can open it with a text editor.)
If you want to get more than a single page, check out the wget command.
Cookies on the World Wide Web
When visiting websites, it's not uncommon for a site to install a cookie--a small data file containing identifying you as a visitor to that site--on your computer. The benefit to cookies is that the information on them can be used to assist in identifying you as an Amazon customer or a Battle.net gamer. The bad news is that the identifying information in cookies can be used to identify you across multiple sites, businesses, and ad agencies. If you've ever done a search for a product on Google, and then seen ads for that same product on a different website... welcome to the wonderful world of cookies.
Cookies are usually stored somewhere in the user library on your computer, possible in a database file. You can prohibit these cookies from being installed by setting your Security Preferences to not accept them, but most sites that require a login won't work without them. You can also delete them by using the options in the Security Preferences.
To view the cookies a website has installed on your computer, find out how by googling the name of your browser and "how to view cookies" or something similar.
Working with Digital Images
Working with digital images is a lot of fun, and includes analyzing the red-, green-, and blue-channels of color in a 2-dimensional grid of picture elements ("pixels").
If you have the Processing platform installed, you might find either one of these two templates useful.
Reading in data from a text file
If you wish to write a program to analyze a text file that has been given to you, you'll need to read the data from that file into your program.
Here's a data file with a bunch of numbers. Can you write a program to add them all? (The answer is....)
Assuming the text file that you've downloaded is available to your program (probably in the same directory)...
- Using Python
- Download quick_dirty_reader.py to see how to quickly analyze text in a file.
- Download PythonDataAnalysis.zip to see a file_reader function, and a line_to_token function, along with a main program that demonstrates how to use those functions to analyze a text file. The main also demonstrates how to use loops to perform simple analysis on the text.
- Using Java
- Download QuickDirtyReader to see how to quickly analyze text in a file.
- Download JavaDataAnalysis.zip to see a FileReader utility, and a FileReaderDemo that demonstrates how to use that utility to read in a text file. The Demo also demonstrates how to use loops to perform simple analysis on the text.
Working with large integers
If you wish to write a program that works with very large integer values, sometimes special precautions are required.
- Using Python
Python uses "arbitrary-length precision," and so math operations require no special precaution (except in some rare special cases using certain libraries). Python2 and Python3 will not produce overflow errors, so you can use standard math operators on numbers with any number of digits. - Using Java
Java does have limits on how many digits an integer can have. If you exceed these limits, no error messages are produced—you just get an incorrect value.
1000000 * 1000000 --> -727379968 // Wait, what? int overflow error
To use arbitrarily long integer values in a calculation, Java requires that you use theBigIntegerclass, an example of which is given below.
1000000 * 1000000 --> 1000000000000
/**
* FibonacciLoopBigInteger calculates Fibonaccis using
* the `BigInteger` class.
*
* The `BigInteger` class allows a Java program to calculate
* with integers that are so large that they would otherwise
* produce overflows. The largest `int` value that Java
* can manage is 2147483647 (= 2^31 - 1), and the largest `long`
* value that Java can work with is 9223372036854775807
* ( = 2^63 - 1). To calculate a larger value, say the 100th
* Fibonacci number, one must use the `BigInteger` class.
*
* To use this class, an integer has to be defined using the
* `.valueOf()` method, and mathematical operations have to be
* performed using methods, such as the `.add()` method. Further
* information about the `BigInteger` class can be found in the
* Java API.
*
* @author Richard White
* @version 2021-11-26
*
*/
import java.math.BigInteger; // Needed to avoid int overflows!
public class FibonacciLoopBigInteger
{
/**
* The fibonacci() method gets the nth fibonacci number, where
* n1 = 1
* n2 = 1
* n3 = 2
* n4 = 3, etc.
* Also supports n0 = 0.
* @param n the index of the Fibonacci number needed
* @return the nth Fibonacci number
*/
public static BigInteger fibonacci(int n)
{
if (n == 0) return BigInteger.valueOf(0);
else if (n == 1) return BigInteger.valueOf(1);
else if (n == 2) return BigInteger.valueOf(1);
else
{
BigInteger n1 = BigInteger.valueOf(1);
BigInteger n2 = BigInteger.valueOf(1);
BigInteger fib = BigInteger.valueOf(0);
for (int i = 3; i <= n; i++)
{
fib = n1.add(n2);
n1 = n2;
n2 = fib;
}
return fib;
}
}
public static void main(String[] args)
{
System.out.println("Example of overflow: 1000000 * 1000000 --> " + 1000000 * 1000000);
System.out.println("Integer.MAX_VALUE --> " + Integer.MAX_VALUE);
System.out.println("Long.MAX_VALUE --> " + Long.MAX_VALUE);
System.out.println("Calculations using the BigInteger class:");
System.out.println("fibonacci(0) --> " + fibonacci(0));
System.out.println("fibonacci(1) --> " + fibonacci(1));
System.out.println("fibonacci(5) --> " + fibonacci(5));
System.out.println("fibonacci(10) --> " + fibonacci(10));
System.out.println("fibonacci(100) --> " + fibonacci(100));
System.out.println("fibonacci(1000) --> " + fibonacci(1000));
}
}
The Command Line
Launch a Terminal application and you'll see a command-line prompt, usually a $ or a % for a regular user or a # for a super-user. You should know that issuing commands at the command line typically gives you a greater power over what can happen on your computer, and making a mistake can have disastrous consequences involving data loss.
Attention!
You should always have a current backup of your entire hard drive so that you can restore from it in the event of catastrophic loss of data.
The man pages
As we cover commands, basic instruction and examples will be given here as well as occasional online references, but the ultimate reference is the man page for these tools.
To learn about grep, for example, at the command line one would enter
$ man grep
to get information about that command.
There is more to this document, and to navigate through it, you'll need to issue some keyboard commands. Your mouse won't work here.
Navigating man pages with less
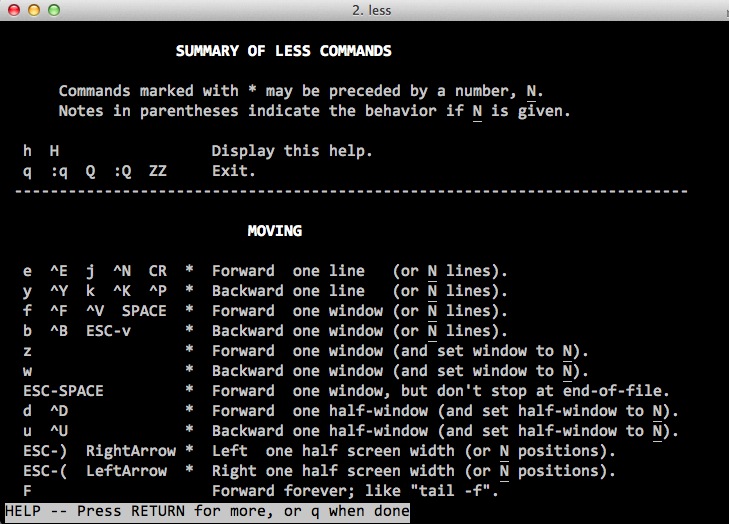
When you use a command like man grep to look at the manual for a page, you're actually using a command-line tool called less. Although you can do a lot with less (!), the most useful commands at this point will be these four:
- f moves forward one page (screen)
- b moves back one page (screen)
- /yourKeyword does a search for the text yourKeyword in the document. Use the
nkey to continue searching for additional occurrences of that word in the document. (N searches backwards for the keyword.) - q will let you quit the
lesstool
If you want to learn what other commands are available to you...
- h reveals the extensive help documentation for navigating through a less-displayed document
grep command to find text
A regular expression is a sequence of characters that form a "search pattern" that can be used for finding text, or finding and replacing text. On the command line, the tool used to look for these text patterns is grep.
For example, if I want to find all the files in my home directory that have my Social Security number listed in them:
$ grep -r '513-20-1894' ~
This search begins in the home folder (~), searches recursively down into the subdirectories (-r), and returns a list of the files that contain that number, along with a couple of lines before and after that number for context.
If I want to search for any sequence of numbers separated by dashes, I'd do this:
$ grep -r --color [0-9] ~
This searches for groups of digits, and highlights the digits when the output is displayed.
grep is an enormously powerful tool with many different options. Use Google to find additional information.
find command to find files
You can find files and directories by filename by using the find command:
$ find <directory> -name <filename>
The command find . -name ctf will start looking recursively in the current directory (.) for a file or directory with the name ctf.
The find command is extraordinarily powerful, and has lots of flags that you can use to modify its use. Some important ones:
- starting in the home directory
~, looks for directories only, with case-insensitive name CTFfind ~ -type d -iname CTF
- starting in the home directory, looks for files only, with the letters
ctfin them, with perhaps additional characters at the beginning or end of the filenamefind ~ -type f -iname "*ctf*"
- finds files in the Music directory that have a filesize greater than 100MB
find ~/Music -size +100M
- finds a graphic file that has been created/modified within the last 14 days
find . -type f -iname "*.jpg" -mtime -14
- finds all the .java files in the directory
apcompsciand pipes them out to thecatcommand which displays them in the terminalfind ~/Documents/apcompsci/ -name '*.java' -print0 | xargs -0 cat
- finds html files and identifies which ones have the string rwhite@crashwhite.com in them
find . -name '*.html' | xargs grep -l 'rwhite@crashwhite.com'
- do a find/replace recursively. Use with caution!
find ./ -type f -exec sed -i "" 's/ReplaceThis/WithThis/' {} \;
diff command to find differences
It is often the case that you'll want to compare two files. It isn't a problem to open two file windows and compare two files that are only 20 lines in length, but when the files get to be 2000 lines long, or even more, we need a more powerful tool for analyzing the differences between them.
The diff command allows you to do this.
$ diff file1.py file2.py
1c1
< #!/usr/bin/env python2.6
---
> #!/usr/bin/env python3
4c4
< file1.py
---
> file2.py
6c6
< @version 2017-04-27
---
> @version 2017-05-01
10,11c10,11
< print "This program is amazing!"
< integer_value = input("Enter a numeric value: ")
---
> print("This program is amazing!")
> integer_value = eval(input("Enter a numeric value: "))
13c13
< print result
---
> print(result)
15c15,16
< main()
---
> if __name__ == "__main__":
> main()
Usually, though, it's better to be able to see the two files side-by-side:
$ diff -y file1.py file2.py
#!/usr/bin/env python2.6 | #!/usr/bin/env python3
""" """
file1.py | file2.py
@author Richard White @author Richard White
@version 2017-04-27 | @version 2017-05-01
""" """
def main(): def main():
print "This program is amazing!" | print("This program is amazing!")
integer_value = input("Enter a numeric value: ") | integer_value = eval(input("Enter a numeric value: "))
result = integer_value + 1 result = integer_value + 1
print result | print(result)
main() | if __name__ == "__main__":
> main()
Or sometimes you just want to see the differences in the two files:
$ diff -y --suppress-common-lines file1.py file2.py
#!/usr/bin/env python2.6 | #!/usr/bin/env python3
file1.py | file2.py
@version 2017-04-27 | @version 2017-05-01
print "This program is amazing!" | print("This program is amazing!")
integer_value = input("Enter a numeric value: ") | integer_value = eval(input("Enter a numeric value: "))
print result | print(result)
main() | if __name__ == "__main__":
> main()
Analyzing files - hexdump
The Hexadecimal Number System
You certainly already know that data on computers is stored in binary form--everything is encoded as 0s and 1s. One of this 0s or 1s is called a bit, for binary digit.
You may have heard of a byte as well, an 8-bit sequence of bits. 01000001 is a byte, in this case, one that represents the number 65, which in ASCII represents the character A. So the letter A, if it needs to be encoded in a form that your computer can use, is represented by the those eight bits, or that byte 01000001.
In this brief discussion we've already used two number systems: the decimal system, base-10, with ten symbols that run from 0-9; and the binary system, base-2, with two symbols, 0 and 1.
It's occasionally the case that computer people will use base-16 in their work, also called hexadecimal. The hexadecimal system includes sixteen symbols: 0 through 9 for the values 0 through 9, and then a for one more than 9 ("10" in base 10), b for two more than 9 ("11" in base 10), all the way up to f.
It may help you to see these values in a table.
| Decimal | Binary | Hexadecimal |
| 00 | 00000000 | 00 |
| 01 | 00000001 | 01 |
| 02 | 00000010 | 02 |
| 03 | 00000011 | 03 |
| 04 | 00000100 | 04 |
| 05 | 00000101 | 05 |
| 06 | 00000110 | 06 |
| 07 | 00000111 | 07 |
| 08 | 00001000 | 08 |
| 09 | 00001001 | 09 |
| 10 | 00001010 | 0a |
| 11 | 00001011 | 0b |
| 12 | 00001100 | 0c |
| 13 | 00001101 | 0d |
| 14 | 00001110 | 0e |
| 15 | 00001111 | 0f |
| 16 | 00010000 | 10 |
| 17 | 00010001 | 11 |
| 18 | 00010010 | 12 |
| 19 | 00010011 | 13 |
| 20 | 00010100 | 14 |
| etc. | etc. | etc. |
There is a more complete listing of decimal, hexadecimal, and octal numbers, along with their ASCII representations, here.
Why is this important to us? Just as a text editor allows us to see what's in a text file, we have tools that allow us to see binary files. We can use the hexdump tool to examine these files.
The hexdump tool
Seeing the ones and zeros in a binary file is not interesting and of little use to us, but we can use hexdump to display the contents of a file in hexadecimal, as well as to display the ASCII version of those bits, which is occasionally useful.
Here's an example of using hexdump to examine a graphic file (just the first few lines of the output are shown):
$ hexdump myPhoto.jpg
0000000 ff d8 ff e0 00 10 4a 46 49 46 00 01 01 01 00 48
0000010 00 48 00 00 ff db 00 43 00 01 01 01 01 01 01 01
0000020 01 01 01 01 01 01 01 01 01 01 01 01 01 01 01 01
0000030 01 01 01 01 01 01 01 01 01 01 01 01 01 01 01 01
0000040 01 01 01 01 01 01 01 01 01 01 01 01 01 01 01 01
.
.
.
Not terribly useful, perhaps, but we can get a look at the ASCII version of whatever binary representations of text there might be in there. Use the -C flag:
$ hexdump -C myPhoto.jpg
00000000 ff d8 ff e0 00 10 4a 46 49 46 00 01 01 01 00 48 |......JFIF.....H|
00000010 00 48 00 00 ff db 00 43 00 01 01 01 01 01 01 01 |.H.....C........|
00000020 01 01 01 01 01 01 01 01 01 01 01 01 01 01 01 01 |................|
00000030 01 01 01 01 01 01 01 01 01 01 01 01 01 01 01 01 |................|
00000040 01 01 01 01 01 01 01 01 01 01 01 01 01 01 01 01 |................|
That JFIF means something, perhaps? Google it to find that JFIF stands for JPEG File Interchange Format. There is all sorts of information hidden in a binary file.
Oh, and if you really want to see the 0s and 1s in that binary file:
$ xxd -b myPhoto.jpg
For more information on some of the ways you can use hexdump, see the man page, or visit https://www.suse.com/communities/conversations/making-sense-hexdump/.
Chaining *NIX commands
The series of small bash utilities that run in the terminal—commands like ls, cat, etc.—are designed to be used with each other. The can easily be chained together by using one of a few common strategies.
Piping commands
Output from running one command in a terminal session can be "piped" as input into a second command. We've already seen an example of this above, in looking at the find command. Let's see another example.
There's a utility called wc, for "word count," although it can be used to count other things as well. I'm going to find out how many pictures of myself there are on my computer.
$ find ~ -type f -iname "*richard*.jpg" | wc -l
The find command is going to look for any jpg file with the world richard in it, and "pipe" the results of that search to the wc command. With the -l flag on there, I'll count the number of lines produced by the previous command, which turns out yield a result of 537 lines.
Not all of those are actual pictures of me, of course. The file "richards_house.jpg" isn't a picture of me, nor is the file "richards_signature.jpg", but perhaps the 537 is a rough estimate.
Redirecting output
Output from one command can be "redirected" to another place. One common strategy that uses this facility is taking the output of a command and recording it into a textfile for evaluation.
In a terminal, the ps command can be used to identify all the current processes running on the machine.
$ ps aux USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND rwhite 350 6.2 0.9 4077328 78004 ?? S Thu07PM 15:54.85 / _windowserver 207 1.0 1.3 4287432 107700 ?? Ss Thu07PM 85:22.58 / rwhite 553 0.5 0.2 2643132 12928 ?? S Thu07PM 25:21.17 / rwhite 360 0.3 0.9 2960696 72772 ?? S Thu07PM 9:53.53 / _hidd 126 0.2 0.0 2473184 4108 ?? Ss Thu07PM 24:16.12 / rwhite 542 0.1 0.5 2610332 44832 ?? S Thu07PM 27:15.00 / rwhite 24284 0.1 3.2 4375520 265444 ?? S 7:38AM 0:27.17 / . . .
If I want a record of that run, I can redirect the output of the command to a file using the > operator:
$ ps aux > ps_output.txt $
And now, I can view the contents of that file:
cat ps_output.txt USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND rwhite 350 6.2 0.9 4077328 78004 ?? S Thu07PM 15:54.85 / _windowserver 207 1.0 1.3 4287432 107700 ?? Ss Thu07PM 85:22.58 / rwhite 553 0.5 0.2 2643132 12928 ?? S Thu07PM 25:21.17 / rwhite 360 0.3 0.9 2960696 72772 ?? S Thu07PM 9:53.53 / _hidd 126 0.2 0.0 2473184 4108 ?? Ss Thu07PM 24:16.12 / rwhite 542 0.1 0.5 2610332 44832 ?? S Thu07PM 27:15.00 / rwhite 24284 0.1 3.2 4375520 265444 ?? S 7:38AM 0:27.17 / . . .
Analyzing network traffic - tcpdump
Just as hexdump allows you to peek into a file, tcpdump allows you to peek into the traffic on a network. The TCP, or Transmission Control Protocol, is the most common aspect of the Internet Protocol that we all use to communicate over the Internet. TCP is the system by which computers "talk" to each other--over wires or wirelessly--and tcpdump allows us to examine captured packets to find out what the computers are saying to each other.
The process of actually capturing packets using a "sniffer" is beyond the scope of this introductory tutorial, but one you have a capture, you'll need to use something to analyze it. The Wireshark cross-platform application is useful here, or you can use tcpdump in the terminal:
tcpdump -nnvvXS -r /tmp/airportSniffGY3WiI.cap > ~/Desktop/readable.txt
This will copy the output of the dump into a text file called readable.txt that you can examine using a text editor.
Video Tutorials
Here's a collection of video tutorials showing you how to solve a series of picoCTF challenges. You can pick up some additional strategies and techniques here.